
L’algorithme Naive Bayes est l’un des algorithmes de machine learning supervisé les plus anciens et les plus utilisés, notamment pour les problèmes de classification. Malgré sa simplicité et ses hypothèses parfois irréalistes, il reste extrêmement performant dans de nombreux cas pratiques, en particulier lorsqu’il s’agit de données textuelles ou de grands volumes de données.
Principe de fonctionnement
Naive Bayes repose sur le théorème de Bayes, qui permet de calculer la probabilité d’un événement en tenant compte d’informations préalables :

Où :
- C est une classe (ex : spam / non spam)
- X est un ensemble de caractéristiques (features)
- P(C) est la probabilité a priori de la classe
- P(X|C) est la probabilité d’observer X sachant C
L’aspect « naïf » de Naive Bayes vient de l’hypothèse suivante :
Les caractéristiques sont conditionnellement indépendantes entre elles, sachant la classe.
Cela signifie que chaque variable est supposée contribuer indépendamment au résultat final, ce qui est rarement vrai dans la réalité, mais fonctionne étonnamment bien dans la pratique.
Pour chaque classe possible, l’algorithme calcule les différentes probabilités. La classe ayant la probabilité la plus élevée est alors choisie selon l’expression suivante :
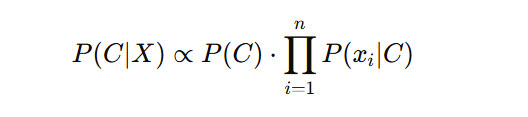
Cas d’application
Marketing et E-Commerce
- Classification de clients (intéressé / non intéressé)
- Analyse de sentiments des avis clients
- Recommandation de produits basée sur des comportements simples
Cybersécurité
- Détection des spams dans les emails
- Identification de messages frauduleux (pishing)
- Filtrage de contenus malveillants
Santé
- Aide au diagnostic médical
- Classification de maladies à partir de symptômes
- Analyse de données biologiques ou cliniques
Finance
- Evaluation du risque de crédit
- Détection de transactions frauduleuses
Industrie et maintenance
- Classification des pannes
- Analyse prédictive des défaillances
- Analyse des retours utilisateurs
- Catégorisation automatique des tickets de support
Ressources humaines
- Tri automatique de CV
- Prédiction de compatibilité entre profils et postes
Exemple concret
On souhaite déterminer si un email est Spam ou Non Spam en fonction des mots qu’il contient. Supposons qu’on dispose des données d’entrainement ci-après :
| Contient “gratuit” | Contient “urgent” | Classe | |
|---|---|---|---|
| 1 | Oui | Oui | Spam |
| 2 | Oui | Non | Spam |
| 3 | Non | Oui | Spam |
| 4 | Non | Non | Non Spam |
| 5 | Non | Non | Non Spam |
Etape 1 : à partir des données (tableau ci-dessus) on va déterminer les probabilités à priori. On obtient ainsi : P(Spam) = 3 / 5 et P(Non Spam) = 2 / 5.
Etape 2 : on cherchera les probabilités conditionnelles. On obtient ainsi : P(gratuit | Spam) = 2 / 3 ; P(urgent | Spam) = 2 / 3 ; P(gratuit | Non Spam) = 0 / 2 et P(urgent | Non Spam) = 0 / 2.
Etape 3 : cette dernière étape consistera à effectuer la prédiction si un email est ou non un spam en fonction de son contenu. Pour un email contenant “gratuit” et “urgent” :
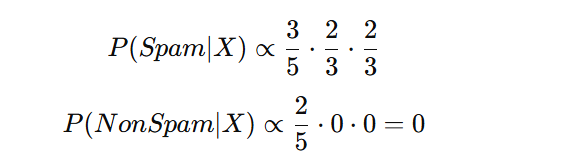
L’email est donc classé comme étant un Spam.
Naive Bayes est un algorithme simple mais puissant, particulièrement adapté aux tâches de classification rapide et aux données textuelles. Malgré son caractère « naïf », il constitue souvent un excellent point de départ pour un projet de machine learning et reste largement utilisé dans l’industrie.